
In dieser Blogserie gehen wir näher auf Elasticsearch ein und widmen uns dabei verschiedenen Fragestellungen:
Folgende Themen sind in der Serie behandelt oder geplant:
- Einrichten einer Elastisearch-Instanz
- Einrichten von Kibana und das Aufsetzen eines ersten Index
- Indizierung von Dokumenten, Mapping von Meta- und Geodaten
- Anbindung von SharePoint oder ähnlichen Informationsportalen
- Sicherheit mit Apache2/ LDAP und das Erstellen von Dashboards und Auswertungen
Im zweiten Teil dieser Blog-Serie wollen wir uns mit Kibana beschäftigen, der grafischen Oberfläche für Elasticsearch.
Einrichten von Kibana und das Aufsetzen eines ersten Index
Hier verwenden wir Kibana Version 4.5.2. Kibana ermöglicht dem Benutzer die schnelle Suche und Analyse neuer Daten über eine GUI mit extrem wenig Zeitaufwand und Vorkenntnissen. Es lassen sich aber auch komplexe Dashboards mit verschiedensten Visualisierungen bauen.
Seit geraumer Zeit gibt es in Kibana ein praktisches und flexibles Plugin Ecosystem. Dieses hilft verschiedenste zusätzliche Visualisierungen mit einem Kommandozeilenaufruf nach zu installieren. Neben diesen Visualisierungs-Plugins gibt es noch App-Plugins wie:
- Sense, eine im Browser aufrufbare REST-Schnittstelle für Elasticsearch
- Shield, ein kostenpflichtiges Plugin zur Erhöhung der Sicherheit und der Einführung von Logins für den Zugriff
- Timelion, eine App, um zeitbasierte Graphen bauen zu können
- Graph, bietet die Möglichkeit Beziehungen in Daten zu visualisieren und
- Marvel, ein Dashboard zur Überwachung von Elasticsearch Clustern
In Zukunft, ab Kibana Version 5.0, wird es möglich sein, ganze Erweiterungspacks als Plugins zu installieren. Diese sollen dann verschiedene Funktionen zusammenfassen und bündeln. Beispielsweise wird X-Pack die Plugins Shield, Marvel und Watcher vereinen.
Neben dem Kibana-Plugins gibt es aber auch noch verschiedene Derivate oder Wettbewerbsprodukte, um Inhalte von Elasticsearch-Indexen zu visualisieren. Die wichtigsten zu erwähnenden Produkte sind Grafana und Kibi. Während Grafana auf die Visualisierung von Zeitserien und komplexen Metriken spezialisiert ist, kann man mithilfe von Kibi Business-Intelligence-Analysen durchführen und visualisieren.
Einrichten der Kibana Instanz
Im Folgenden werden wir Kibana installieren, einrichten und erstmalig aufrufen.
- Als erstes muss man die Kibana-Installation von folgender Quelle herunterladen: https://www.elastic.co/downloads/kibana
Hierbei ist es im Gegensatz zu Elasticsearch wichtig, die richtige Betriebssystem Version herunterzuladen, da Kibana das passende NodeJS Binary benötigt. Weiterhin ist auch auf die Kompatibilität mit der passenden Elasticsearch Version zu achten. - Kibana kann entweder auf einem Server oder auf einem Client Rechner als Anwendung gestartet werden. Nach dem Entpacken der Installationsdatei kann Kibana durch einen einfachen Commandline Aufruf gestartet werden. Innerhalb des CMD-Fensters sollte man in den entpackten Ordner wechseln und folgenden Aufruf tätigen:
bin\kibana.bat - Nun kann Kibana unter folgender URL mit dem Browser aufgerufen werden: http://localhost:5601/
In der Datei kibana.yml im Verzeichnis config können verschiedenen Konfigurationseinstellungen angepasst werden:
- Standardmäßig wird Kibana versuchen Elasticsearch unter der Adresse http://localhost:9200 anzubinden. Die Adresse kann jedoch angepasst werden.
- Als Standardport für Kibana wird 5601 verwendet. Änderungen könne ebenfalls konfiguriert werden.
- Wenn keine weiteren Einstellungen vorgenommen werden, kann Kibana aus Sicherheitsgründen nur lokal aufgerufen werden. Falls der Zugriff über den Rechnernamen innerhalb des Netzwerkes möglich sein soll, muss folgender Eintrag vorhanden sein: server.host: "0.0.0.0"
Anlegen eines Index in Elasticsearch
Da bisher kein Index angelegt ist, können wir momentan auch keine Daten in Kibana anzeigen. Prinzipiell kann ein Index auf verschiedene Arten angelegt werden. Dafür müssen wir auf die REST-Schnittstelle von Elasticsearch zugreifen. Am einfachsten ist dies mit dem Commandline Tool „cURL", welches auch für Windows unter folgender Adresse verfügbar ist:
http://www.confusedbycode.com/curl/
Nach der Installation und einem Neustart kann „cURL“ nun in einem Kommandozeilen Fenster verwendet werden.
Ein leerer Index kann folgendermaßen angelegt werden:
curl -XPOST http://localhost:9200/projekte („projekte“ ist der Name des Index)
Löschen kann man einen Index mit diesem Aufruf:
curl -XDELETE http://localhost:9200/projekte
Alternativ, kann man den Index gemeinsam mit einem Mapping anlegen. Jedoch werden wir dieses komplexere Thema erst im nächsten Teil der Blogserie besprechen.
- In diesem Beispiel legen wir nun den Index an, indem wir ihn gleich mit Daten befüllen. Dafür müssen folgende cURL Aufrufe durchgeführt werden. Wichtig ist, dass wir dem Index „projekte“ einen Eintrag des Typen „projekt“ über die URL hinzufügen.
http://localhost:9200/INDEX/EINTRAG/
Nachfolgend sind einige cURL-Aufrufe mit Beispieldaten zu finden, die in den späteren Beispielen verwendet werden. Für eigene Tests können hier beliebige weitere Musterdaten angelegt werden.
curl -H "Content-Type: application/json" -X POST http://localhost:9200/projekte/projekt/ -d "{\"branche\" : [ \"Sonstiges\" ],\"schlagworte\" : [ \"Mitgliederverwaltung\", \"Kontoführung\", \"Mahnwesen\", \"Organisationsstruktur\", \"FIBU-Schnittstelle\", \"Migration\", \"Struts\", \"iText\", \"BIRT\", \"AXIS\", \"tomcat\", \"Eclipse\", \"Hibernate\", \"Oracle 10g\", \"PostgreSQL\", \"Magic Draw\", \"UML\" ],\"kompetenzbereich\" : [ \"IT-Projekt\" ]}"
curl -H "Content-Type: application/json" -X POST http://localhost:9200/projekte/projekt/ -d "{\"branche\" : [ \"Logistik\" ],\"schlagworte\" : [ \"Java EE 7\", \"JPA\", \"JAX-RS\", \"Glassfish\", \"Vaadin 7\", \"JUnit\", \"GIT\", \"Eclipse\", \"Coach\", \"Architekturreview\", \"ATAM\", \"CDI\", \"Kepler\" ],\"kompetenzbereich\" : [ \"Technologieberatung\" ]}"
curl -H "Content-Type: application/json" -X POST http://localhost:9200/projekte/projekt/ -d "{\"branche\" : [ \"Automotive\" ],\"schlagworte\" : [ \"B2V\", \"Remote Services\", \"Sixt\", \"Java 5\", \"Java EE 5\", \"HTTP\", \"Web Service\", \"Oracle 10g\" ],\"kompetenzbereich\" : [ \"IT-Projekt\" ]}"
curl -H "Content-Type: application/json" -X POST http://localhost:9200/projekte/projekt/ -d "{\"branche\" : [ \"Industrie; Maschinenbau\" ],\"schlagworte\" : [ \"J2EE\", \"Liferay\", \"CAS\", \"JBoss\", \"tomcat\", \"MySQL\", \"Velocity\", \"Hibernate\", \"Ant\" ],\"kompetenzbereich\" : [ \"IT-Management\", \"IT-Projekt\" ]}"Wenn ein cURL-Aufruf erfolgreich war, wird ein Eintrag folgender Art zurückgegeben:
{"_index":"projekte","_type":"projekt","_id":"AVXuZF6GHuMmDSP_puY_","
_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}
Verwendung des Elasticsearch Index in Kibana
Als nächstes müssen wir nun den Index in Kibana einlesen und anlegen
- Kibana im Browser aufrufen: http://localhost:5601/
- Gehe zu „Settings“ und trage den Indexname „projekte“ ein. Dabei beachten, dass keine Häkchen bei „Index contains time-based events“ gesetzt ist. Dann bitte den Button „Create“ auswählen. Wenn dieser Button nicht erscheint, kann Kibana diesen Index in Elasticsearch nicht finden. In diesem Fall bitte prüfen, ob das Anlegen erfolgreich war (vorheriger Punkt).
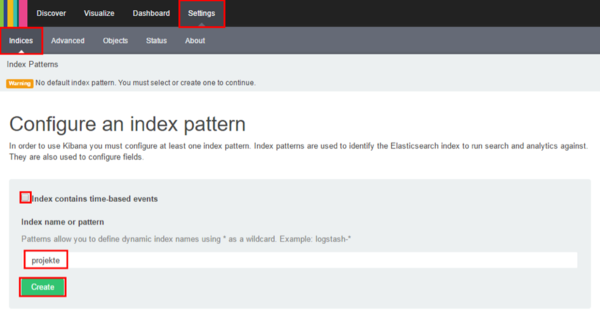
- Nach Anlegen sollte nun folgendes zu sehen sein:
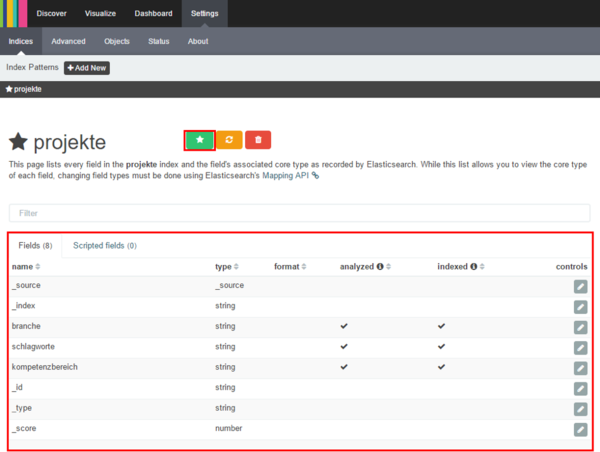
- Durch Drücken der Sterntaste wird dieser Index als Standard ausgewählt. Im Bereich „Fields“ werden die einzelnen Felder und Zusatzinformationen angezeigt. Wenn Elasticsearch nicht explizit über ein Mapping mitgeteilt wird welchen Typ ein Feld hat, wird dieser bestmöglich erraten. Wie wir sehen können, wird den meisten Feldern der Typ „String“ zugewiesen. Auch können wir sehen, dass unsere eingegebenen Inhalte alle „analyzed“ und „indexed“ sind.
- „Indexed“ bedeutet, dass diese Felder durchsuchbar sind.
- „analyzed“ bedeutet, dass die Inhalte des Feldes gemäß den Regeln eines Analyzers heruntergebrochen werden. Das bedeutet, dass beispielsweise Sätze in ihre Einzelwörter aufgebrochen werden oder gewisse Füllwörter oder Satzzeichen entfernt werden. Dies kann wiederum dazu führen, dass man bei Analysen auf bestimmten Feldern keine Begriffe mit mehreren Wörtern korrekt quantifizieren kann. Die Begriffe „Big Data“ und „Data Mining“ würden dann folgendes ergeben: 2 x Data, 1 x Big und 1 x Mining.
Auf Basis der eingespielten Daten kann man nun mit Kibana arbeiten. Wir werden dies anhand von Beispielen erläutern. Weitere Details kann man dem Kibana User Guide entnehmen: https://www.elastic.co/guide/en/kibana/current/index.html
Suche und Visualisierung mit Kibana
Als Teil dieses Blogeintrages werden wir eine kurze Einführung zu den drei verschiedenen Bereichen, Discover, Visualize und Dashboard in Kibana geben. Diese werden wir mit einfachen Beispielen illustrieren. Weitere Details und das Erstellen komplexerer Dashboards werden wir in einem späteren Teil der Blogserie besprechen.
Discover
Im Bereich Discover kann man frei nach Inhalten suchen oder Listen zusammenstellen und speichern. Hierzu kann man Begriffe im Suchfeld eingeben nach den gesucht bzw. gefiltert wird. Die relevanten Suchbegriffe werden Gelb hinterlegt; auch wird die Anzahl der Hits angezeigt.
- Für unser Beispiel geben wir den Suchstring „Logistik OR Industrie“ ein. Durch die Verknüpfung mir „OR“ werden bei dieser Suche Ergebnisse beider Begriffe angezeigt.
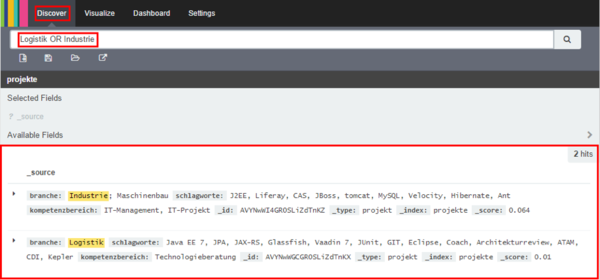
- Wenn erforderlich, kann man in diesem Bereich auch das Layout der Suchergebnisse (Reihenfolge etc.) und welche Felder angezeigt werden festlegen.
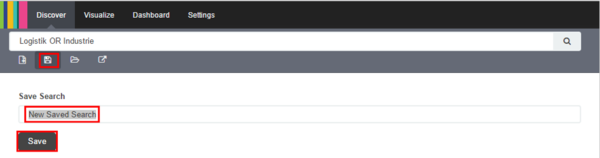
- Damit wir unsere Suche in ein Dashboard einbinden können, müssen wir diese nun abspeichern. Hierzu wählt man in der Haupttaskleiste das „Disketten-Symbol“, wählt einen Namen für die Visualisierung aus und speichert über den „SAVE“-Button.
Visualize
Im Bereich Visualize kann man Daten in verschiedenen Formen visualisieren und diese sichten für eine spätere Verwendung z.B. in einem Dashboard speichern.
- Für unser Beispiel wählen wir den Typ „Pie chart“ aus.
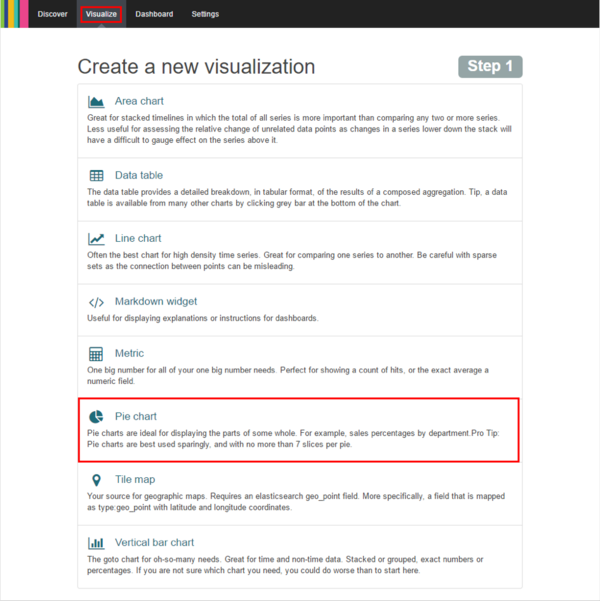
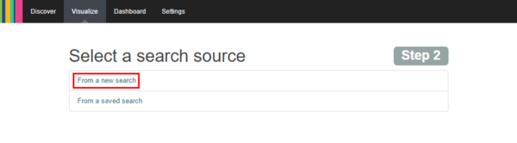
- Als nächstes wählen wir als Source „From a new search“ aus.
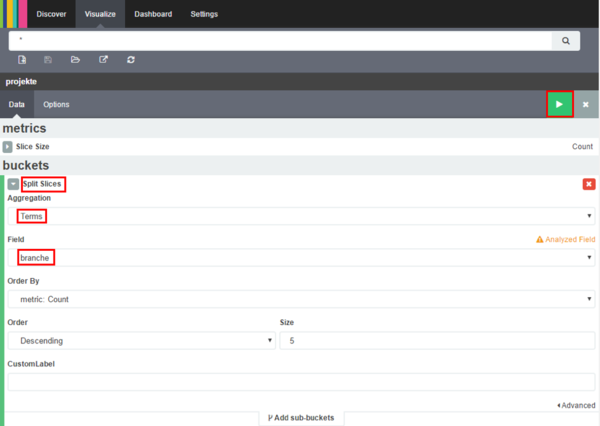
- Wir wählen unter „buckets type“ die Option „Split Slices“. Dann wird im Dropdownmenü „Aggregation“ die Option „Terms“ ausgesucht. Zuletzt wählen wir ein „Field“, z.B.: „branche“ und drücken auf den grünen „Play“-Button.
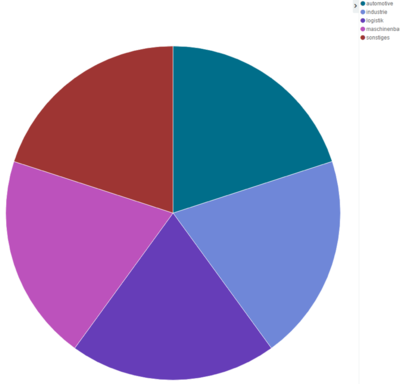
- Nun sehen wir einen „Pie Chart“ mit unseren Top 5 Branchen aus unseren Dateneinträgen.
- Damit wir unsere Visualisierung in ein Dashboard einbinden können, müssen wir diese nun abspeichern. Hierzu wählt man in der Haupttaskleiste das „Disketten-Symbol“. Wählt einen Namen für die Visualisierung aus und speichert über den „SAVE“-Button.

Dashboard
Dashboards ermöglichen das Zusammenstellen verschiedener Suchen und Visualisierungen in einer übersichtlichen Oberfläche. Diese kann wiederrum gespeichert werden.
- Als Beispiel werden wir unsere gespeicherte Suche und Visualisierung in ein Dashboard einbinden. Im Bereich Dashboard kann man über die Anwahl des + Symbols ein Element hinzufügen. Hier wählen wir zuerst die vorab gespeicherte Visualisierung aus.
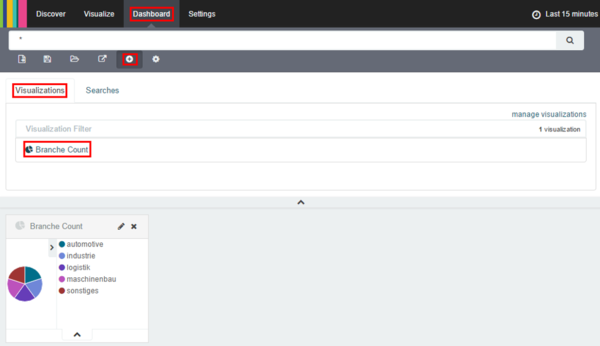
- Als nächstes fügen wir unsere gespeicherte Suche in das Dashboard ein.
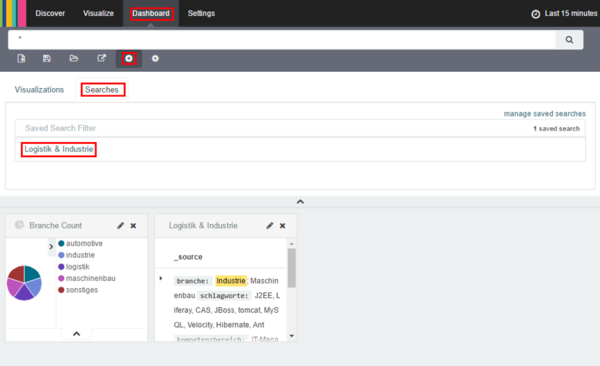
- Nun können wir final das Layout durch Drag & Drop anpassen und unser Dashboard abspeichern.
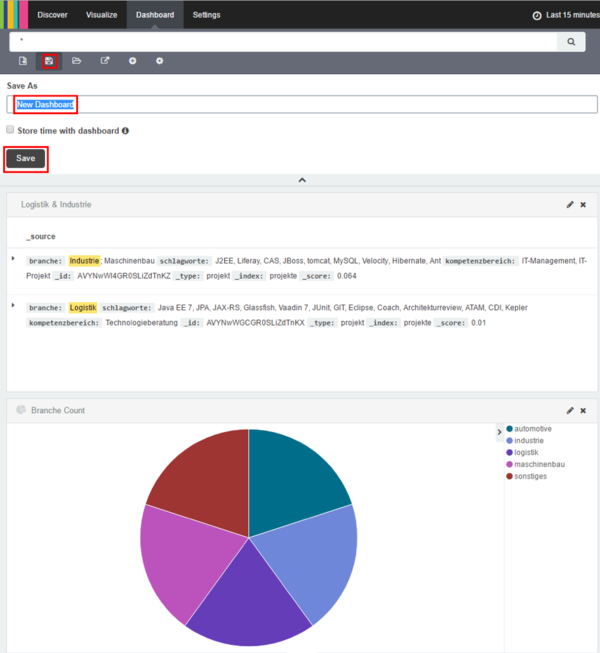
- Im Suchfeld in der Haupttaskleiste kann man wiederrum im Suchfeld seine Ergebnisse einschränken.
- Mit diesen wenigen, einfachen Schritten haben wir uns nun ein Dashboard zusammengestellt.
Im nächsten Blogeintrag widmen wir uns dem Indizieren von Dokumenten, dem Mapping der Index-Daten, das wir hier schon mehrfach erwähnt hatten und dem Einspielen und Visualisieren von Geodaten.
![]() Nico Heinze - ist Projektmanager bei der iteratec GmbH in München. In den vergangenen Jahren setzten sein Team und er immer wieder völlig neuartige Anwendungen um.
Nico Heinze - ist Projektmanager bei der iteratec GmbH in München. In den vergangenen Jahren setzten sein Team und er immer wieder völlig neuartige Anwendungen um.